
(Corpus Audio d’Étudiants Natifs et non-NAtifs en InteractionS)
Projet pédagogique
Le projet CAENNAIS est un projet pédagogique commencé en octobre 2023 et réalisé par une équipe de recherche constituée de membres du Laboratoire CRISCO et des étudiants en Science du Langage et en Orthophonie de l’Université de Caen Normandie. Le corpus CAENNAIS est un corpus longitudinal d’interactions entre des locuteurs francophones natifs et des apprenants en immersion en France. Le projet a pour but de produire et de mettre à disposition des chercheurs un corpus d’apprenants transcrit et annoté ainsi que de former les étudiants stagiaires aux bonnes pratiques de la collecte, la transcription et l’annotation des données orales et au travail d’équipe.
2023-2024
Lors de la première phase du projet (septembre 2023-mai 2024) six groupes de participants ont été recrutés et enregistrés par les étudiants stagiaires Orlanne Pinsault et Florian Peck trois fois au cours de l’année résultant en 18 heures d’enregistrements dont 90 minutes ont été transcrites en suivant un guide de transcription développé par l’équipe (voir Orlanne Pinsault 2024, Constitution d’un corpus oral longitudinal d’apprenants du français : défis et enjeux des outils numériques dans la constitution de corpus. Mémoire de M2).
2024-2025
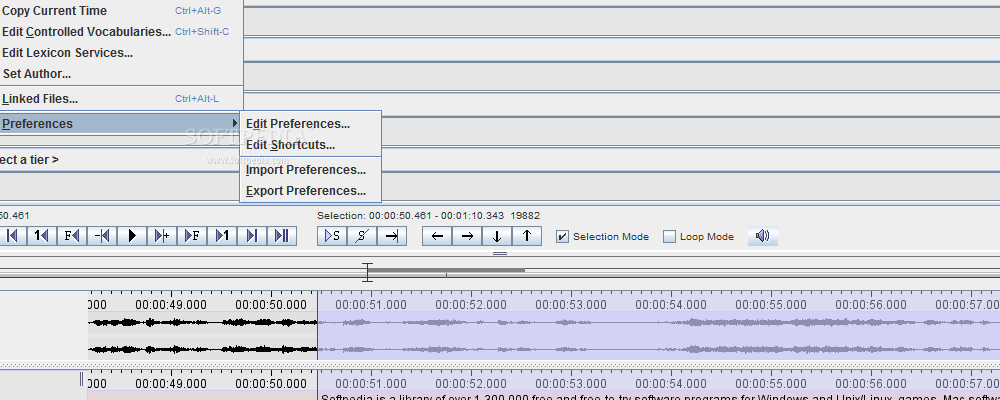
En 2024-2025 l’équipe s’est penchée sur le développement d’une chaîne de traitement pour la diarisation (identification de tours de paroles) et transcription semi-automatiques adaptée à un corpus longitudinal d’interactions de locuteurs de différents niveaux de compétences. Cette démarche implique des campagnes de correction des transcriptions automatiques et homogénéisation des pratiques pour permettre un réentraînement progressif de modèles des outils automatiques (PyAnnote, Whisper). Trois heures d’enregistrements ont été diarisés et transcrits.
Une chaîne de traîtement DIAxASR a été mise en place, un pipeline Python permettant :
- la diarisation automatique de fichiers audio à l’aide d’un modèle Pyannote Audio;
- la segmentation des enregistrements avec export des segments audio et des métadonnées (.tsv, .eaf);
- la transcription automatique avec un modèle Whisper (fine-tuné);
- la mise à jour des fichiers ELAN (.eaf) avec les transcriptions.
2025-2026
En 2025-2026 l’équipe CAENNAIS poursuit la transcription des données tout en les préparant pour l’archivage. Une mise à disposition d’une partie des données est prévue pour la fin 2026.
Dissemination
En juin 2025, l’équipe CAENNAIS a participé au colloque FRAPEOR à l’Universoté d’Orléans avec une intervention intitulée « L’art du dialogue interculturel : adapter les outils de transcription automatique aux données de l’oral spontané » (consulter le programme du colloque). En novembre 2025, Maxence Multin et Rayan Ziane ont présenté un poster sur l' »Adaptation d’outils pour le traitement de la parole spontanée et la création d’un corpus d’interaction » aux Rencontres de jeunes chercheurs en paroles à Paris.
Recherche
En mai 2025, Orlanne Pinsault a soutenu son mémoire de M2 intitulé « Constitution d’un corpus oral longitudinal d’apprenants du français : défis et enjeux des outils numériques dans la constitution de corpus ». Deux mémoires de M2 en Sciences du Langage utilisant les données du corpus CAENNAIS ont été soutenus en septembre 2025 par Maxence Multin (« Intégration du corpus ESLO_REPAS dans le finetuning du modèle de segmentation du projet CAENNAIS: Vers la diversification ou l’homogénéisation des données de finetuning? ») et Florian Peck (« L’évolution des phénomènes interactionnels dans un corpus oral longitudinal : Chevauchements, interruptions et sujets de conversation »).
Équipe
Si vous souhaiter participer au projet ou effectuer un stage non-rémunéré, n’hésitez pas à nous contacter.

