
En amont du logiciel Kali, diverses ressources linguistiques sont utilisées, certaines sous forme de textes (dictionnaires, règles), d’autres sous forme de fichiers générés par un programme de traitement de la parole. Pour plus de détail sur ces ressources, voir description des différentes opérations. Plusieurs petits outils ont été développés pour adapter les ressources textuelles à l’utilisation qui en est faite dans Kali. Ceux-ci sont énumérés ici, ainsi que le programme de traitement de la parole, outil de base indispensable au développement d’un système de synthèse vocale, qui est décrit plus en détail.
Cryptage de données textuelles
Kali faisant l’objet d’une licence de l’université, un petit outil de cryptage a été développé afin que les ressources en format texte ne soient pas livrées en clair. C’est le cas, pour chaque langue, du dictionnaire de diagnostic de langue, du dictionnaire majuscule, du dictionnaire minuscule, du dictionnaire énonciatif, du dictionnaire informationnel, des règles de découpage en tronçons, du dictionnaire de phonétisation et du fichier de prosodie normalisée. Le cryptage est effectué lors de la compilation des ressources textuelles. Lors du démarrage de Kali, ces dictionnaires sont chargés et décryptés par Kali. Le dictionnaire utilisateur, de son côté, reste bien sûr en clair.
Compilation de certains dictionnaires
Plusieurs dictionnaires nécessaires à l’analyse syntaxique se présentent sous des formes voisines, avec sur chaque ligne l’entrée suivie du symbole ’>’ suivi de lettres ou symboles caractérisant cette entrée. Prenons pour exemples une ligne dans chaque dictionnaire, en français :
- Dictionnaire des défigements : -elle>L/fs3
- Dictionnaire des figements : alors/que>u
- Dictionnaire de catégorisation : active>VJ/s13:fs
- Dictionnaire des racines : abdiqu>1
Ces dictionnaires sont compilés sous forme arborescente, avec les paramètres à l’extrémité de chaque branche. Le fichier obtenu est de format binaire.
Compilation des règles particulières
Les règles de conjugaison (associées aux racines) sont réparties en 65 groupes, les formes étant énumérées par ordre décroissant de taille, les catégories grammaticales étant en correspondance. Par exemple :
GROUPE 1
assions eraient erions assent assiez asses erais erons erait aient èrent eront eriez asse erai eras âmes âtes ions erez era ées ais ons ait ant ent iez ée ai er es és as ât ez a e é
V/p1 V/p3 V/p1 V/p3 V/p2 V/s2 V/s12 V/p1 V/s3 V/p3 V/p3 V/p3 V/p2 V/s13 V/s1 V/s2 V/p1 V/p2 V/p1 V/p2 V/s3 E/fp V/s12 V/p1 V/s3 T V/p3 V/p2 E/fs V/s1 I V/s2 E/mp V/s2 V/s3 V/p2 V/s3 V/s31 E/ms
Les suffixes sont répartis par types de catégories grammaticales, par exemple :
…
17 N/fs (énumération des types)
…
$ 17 (développement de chaque type)
ition*nance*icité
Les règles de déduction contextuelle sont constituées de champs (dans l’ordre des mots) séparés par des ’+’, la partie située à gauche de la flèche ’->’ étant testée et la partie droite étant appliquée. Par exemple :
_Cat=d + _Cat=VöëäIôêâTòèà _Cat !JNM -> _Cat=o
Les règles de mise en relation sont structurées de la même façon, les champs n’étant plus des mots mais des tronçons, et les catégories grammaticales étant remplacées par des couleurs (verbale, nominale, etc.) :
_Coul=V _Coul !epiqbu _Relie=0 -> @DepileRelie0
Les règles de phonétisation sont hiérarchisées. Chaque sous-règle commence par un tiret de plus que la règle dont elle est l’exception :
– – ¦*•ch•l* k (chlore, )
Chacun de ces fichiers de règles est compilé d’une façon particulière, dans un format binaire adapté à son utilisation par Kali. La syntaxe des règles de phonétisation est vérifiée par un utilitaire au moment de la compilation. Le compilateur crée également un fichier de test à partir des exemples qui illustrent chaque règle, à destination d’un comparateur (voir programme de comparaison).
Les contours prosodiques naturels – un fichier par contour à la construction – sont regroupés par le compilateur en un seul fichier binaire contenant toutes les valeurs et toutes les clés associées.
À côté de toutes ces ressources déclaratives dont les sources sont en format texte, le fichier de diphones – autrement dit la voix – est un fichier binaire produit par le logiciel de traitement de la parole, dont nous allons parler plus longuement.
Logiciel de traitement de la parole
Cet outil de traitement du signal, du nom de KParole, a été développé afin de constituer des bases de diphones et des fichiers de prosodie à partir de voix naturelles enregistrées. Il permet tout d’abord d’effectuer les opérations de base sur le signal : enregistrer, ouvrir, découper, concaténer, visualiser, diffuser des fichiers son. La puissance des signaux peut être modifiée ou normalisée, pour l’écoute ou pour les enregistrements. Les signaux traités sont à 22 kHz 16 bits mono.
La visualisation des signaux se fait à deux échelles temporelles : une petite échelle grâce à laquelle la totalité du signal est affichée sur la largeur de l’écran, une grande échelle grâce à laquelle le contenu d’une fenêtre déplaçable est affiché sur la largeur de l’écran. Cette fenêtre est de taille ajustable afin que la partie de signal sélectionnée soit visualisée à l’échelle souhaitée.
Des barres verticales de repérage peuvent être posées en cliquant dans une des fenêtres. Ces barres servent à sélectionner la partie à lire ou à enregistrer, visualiser les périodes, repérer les phonèmes, les diphones, etc. Elles peuvent être déplacées à l’aide de la souris ou supprimées à l’aide du clavier. Les opérations qui utilisent deux barres (lecture, enregistrement) le font à l’aide des deux dernières barres activées. De nombreuses fonctions utilisent ces barres.
KParole permet ensuite de calculer de façon semi-automatique le repérage des périodes, opération obligatoire avant tout traitement de la parole. L’origine du repérage est arbitraire, mais au même endroit pour toutes les périodes.
Un filtrage passe-bas à 400 Hz est d’abord effectué afin d’éliminer le bruit et les formants de rang élevé, pour ne conserver que les premiers harmoniques des parties voisées. Ensuite, le signal est auto-corrélé avec un décalage variable, jusqu’à un maximum correspondant théoriquement à la période T. Cependant, si cette méthode fonctionne parfaitement dans une majorité de cas, des maxima peuvent apparaître non seulement pour un décalage de T, mais aussi de 2T ou de T/2, d’où un taux d’erreur non négligeable.
Comme nous voulions un repérage sans erreur, nous avons adopté une méthode semi-automatique en trois étapes : (1) repérage des maxima relatifs d’intensité (un ou plusieurs par phonème voisé) et marquage d’une période pour chaque maximum, (2) propagation des marques de périodes par itération de part et d’autre du maximum, tant que le score de corrélation est suffisant, (3) marquage des parties non voisées par interpolation. L’intervention humaine est ainsi optimisée : après l’étape 1, subsiste environ une erreur toutes les 2 à 10 secondes, dont la correction consiste à modifier seulement une ou deux marques (figure).
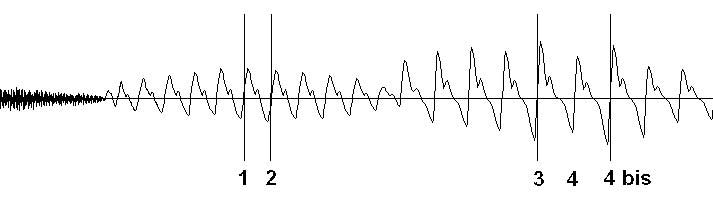
Chaque marque est placée sur la plus grande pente détectée localement. L’intervention humaine permet ici de déplacer la marque (4 bis), erronée, jusqu’à sa position correcte (4).
Ensuite, l’étape 2 bénéficie des marques déjà connues et permet ainsi d’ajouter au score de corrélation celui de la comparaison des durées de deux périodes successives. En clair, il est impossible que la périodicité passe brutalement au double ou à la moitié de la valeur précédente. Les rares erreurs se situent aux frontières des parties voisées, c’est-à-dire aux endroits où l’algorithme itératif doit être arrêté. L’étape 3 a seulement pour fonction de segmenter les parties non voisées de façon à permettre des traitements du même type que ceux des parties voisées. Aucun contrôle n’est nécessaire pour cette dernière étape.
Après ces opérations préliminaires, il est possible de prélever chaque diphone et de choisir le meilleur représentant d’un diphone donné grâce à un calcul de distance spectrale (à l’aide de transformées de Fourier), à la comparaison des paramètres acoustiques et à une comparaison sonore, soit des diphones seuls, soit des diphones à l’intérieur d’un mot sans signification.
Les diphones étant saisis dans des contextes différents, il est nécessaire de les modifier pour que leur raccordement ne présente pas de discontinuités. La hauteur, l’intensité et la durée subissent des opérations de normalisation grâce à un traitement utilisant des fenêtres de mixage sinusoïdales, période par période (voir génération de la parole). La norme pour la hauteur et l’intensité d’un phonème – donc à l’extrémité d’un diphone – est la moyenne des hauteurs et intensités de toutes les occurrences du phonème dans la base de diphones (soit deux fois le nombre de phonèmes différents, soit ici 62 à 110 occurrences selon la langue). De leur côté, les durées dépendent des catégories de phonèmes de part et d’autre du diphone, ce qui représente beaucoup de cas différents mais peu d’occurrences de chaque cas. Les moyennes sur de faibles occurrences représentant une trop grande dispersion, nous avons choisi de créer un tableau de durées guides à partir de statistiques sur un ensemble de données orales – et non sur la seule base de diphones. De plus, lorsque l’une des extrémités est une voyelle, un éventuel allongement – dû à un accent tonique, syntaxique, grammatical ou pragmatique – est neutralisé par une durée guide du côté vocalique, la frontière de la voyelle étant calculée par analyse spectrale.
Pour éviter les discontinuités de timbre et de phase, il faut effectuer un mélange progressif local avec un phonème type obtenu par calcul, sur une ou plusieurs périodes au niveau du raccordement.
Selon le contexte et compte tenu de la variabilité inhérente à un locuteur donné, le timbre d’un même phone peut différer d’une occurrence à l’autre, créant une discontinuité spectrale lors de la concaténation des diphones. Il est nécessaire de lisser cette discontinuité.
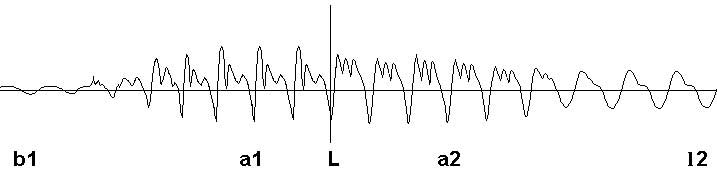
Sur la figure ci-dessus représentant la concaténation des diphones ba et al, la discontinuité de timbre apparaît nettement au niveau de la frontière L. Pour éviter cela, nous définissons une zone de transition aux extrémités des diphones, dans laquelle nous effectuons un mélange progressif de ceux-ci avec un phone type (voir ci-dessous) par fondu enchaîné. Les harmoniques et leurs phases glissent ainsi d’un diphone à l’autre sans discontinuité, en passant par le phone type au moment de la jonction. Cette opération est effectuée par le logiciel de traitement de la parole au moment de la constitution de la base de diphones, afin de diminuer le temps de calcul lors de la production de la parole.
Nous procédons en deux étapes : (1) au moment du prélèvement, un tri des diphones candidats est effectué en fonction de critères d’acceptabilité auditive (nous comparons la qualité de mots fabriqués avec les divers candidats) et d’un score de distance spectrale permettant de minimiser les discontinuités de timbre et ainsi de réduire les phénomènes de diaphonie dus à la deuxième étape ; (2) un mélange progressif (utilisant nos fenêtres sinusoïdales) est effectué aux extrémités du diphone avec un phone type, sélectionné lui aussi à l’aide d’un score de distance spectrale, et prélevé à l’extrémité du diphone qui le contient. A l’issue de ces traitements, les diphones peuvent être concaténés sans discontinuité de timbre, de phase ou de signal.
Afin d’éviter une dégradation progressive de la qualité, la base de diphones est enregistrée en brut, c’est-à-dire avant les différents traitements (hauteur, intensité, durée, timbre), avec seulement les marques de périodes et la liste des phonèmes types. Les traitements sont effectués en temps réel durant le travail de prélèvement et de test, et bien sûr lors de la génération du fichier voix utilisable par Kali.
Pour le prélèvement de la prosodie, le développeur place un repère au milieu de chaque phonème et le programme calcule automatiquement les paramètres acoustiques de l’énoncé. Le contour prosodique est sauvegardé sous forme d’un fichier comportant, pour chaque voyelle de l’énoncé, la hauteur, ses dérivées première et seconde, l’intensité, ses dérivées premières et secondes, et la vitesse de phonation. Ces paramètres sont exprimés sous forme de variations logarithmiques par rapport à la voix de la base de diphones. Le tableau du contour prosodique de la phrase est ensuite scindé manuellement en plus petits tableaux correspondant chacun à un tronçon, identifié par une clé à remplir en entête du tableau (voir Détail du modèle prosodique à base de contours naturels).
Programme de comparaison KCompare
Indispensable à la maintenance des modules d’analyse et de transcription phonétique, ce programme permet de comparer la sortie phonétique – comprenant les balises syntactico-pragmatiques – d’un même corpus entre l’état précédent – ou un état plus ancien – des modules et leur état actuel. Plusieurs corpus sont utilisés pour chaque langue : un dictionnaire de mots classés par ordre de fréquence, y compris noms propres (pour la transcription phonétique), une compilation des exemples qui illustrent les règles de transcription phonétique, un corpus général d’environ 50000 à 100000 mots, aussi varié que possible (pour l’analyse et secondairement la transcription). Ce corpus est composé principalement d’articles de journaux sur tous les types de sujets ainsi que d’extraits de romans avec des dialogues. On y trouve également une notice technique, une interview retranscrite et quelques phrases fabriquées pour la circonstance. Le test différentiel doit être effectué à chaque pas d’évolution des règles et dictionnaires.
Ce programme est extrêmement important car il permet de préserver les règles déjà acquises. Seules les règles modifiées restent à contrôler manuellement. KCompare affiche le texte paragraphe par paragraphe dans une première fenêtre, sa transcription phonétique ancienne avec ou sans les balises dans une deuxième fenêtre et la nouvelle dans la troisième fenêtre. Seuls les paragraphes ayant subi des modifications sont affichés, la partie modifiée en évidence. On peut se déplacer d’une différence à l’autre afin de compter les corrections positives et de prendre note d’éventuels effets négatifs.