
Prétraitement du texte
La toute première opération consiste à découper le texte en paragraphes et en phrases.
La deuxième opération consiste à choisir la langue de travail en fonction d’un diagnostic de langue établi phrase par phrase. L’utilisateur peut forcer une langue donnée.
Le texte subit ensuite une opération de réécriture basée sur des dictionnaires, qui a pour but de faciliter la mise en œuvre des traitements qui suivent, notamment en ajoutant les accents manquants, en gérant les variantes orthographiques et en développant en toutes lettres les abréviations et sigles.
Le dictionnaire de réécriture interne est complété par un dictionnaire utilisateur : en effet, d’une part, le prétraitement ne peut pas être exhaustif, d’autre part, la réécriture par l’utilisateur lui permet de traiter des mots spécialisés, des mots nouveaux et surtout des noms propres oubliés.
Enfin, des balises (index de lecture) sont placées entre chaque mot typographique afin que le moteur de Kali connaisse à chaque instant le mot en cours de lecture (fonction utilisée notamment par les logiciels pour déficients visuels).
À l’issue de ce prétraitement, le texte est prêt pour l’analyse syntaxique et pragmatique.
Analyse syntaxique et pragmatique
L’analyse syntaxique de Kali fournit un découpage du texte en tronçons (branches de syntagmes ou « chunks » en anglais = groupes de mots fortement liés entre eux) ainsi que leurs relations de dépendance (Vergne et Giguet 1998). Cette opération, à la base de la génération automatique de prosodie, est complétée par une analyse pragmatique du texte (Lacheret et Morel 2011) permettant à la prosodie de souligner l’organisation informationnelle et l’expressivité des énoncés.
L’analyse syntaxique s’effectue en 4 phases : (1) la segmentation des phrases en mots, (2) l’étiquetage de ceux-ci (ou catégorisation), (3) leur regroupement sous forme de tronçons, et enfin (4) la mise en relation des tronçons les uns avec les autres. L’analyse pragmatique intervient principalement après l’analyse syntaxique, mais certaines informations spécifiques à l’analyse pragmatique sont obtenues durant la catégorisation grâce aux outils de l’analyseur. C’est pourquoi nous pouvons parler d’une analyse syntactico-pragmatique.
Ces traitements sont réalisés par l’utilisation de dictionnaires et de règles. Des balises d’analyse sont placées dans le texte pour transmettre la structure prosodique au module phonétique. L’analyse syntaxique fournit également des balises de catégorie permettant de désambiguïser la prononciation de certains mots (homographes hétérophones comme président). Enfin, elle fournit des balises de frontière pour le traitement des liaisons (ex : de fidèles amis vs les amis fidèles | existent).
Transcription graphème-phonème
Pour oraliser correctement un texte, il faut appliquer de nombreuses règles de prononciation. L’opération de transcription fournit un texte phonétique à partir du texte alphabétique (Morel et Lacheret 1998). Le français comporte quelques milliers de règles de base ; l’anglais, peu efficace par règles, nécessite en outre un dictionnaire de mots très exhaustif. Les mots d’emprunt et les noms propres du monde entier (même en se limitant à l’actualité) nécessitent dans chaque langue un dictionnaire additionnel contenant des dizaines de milliers de mots.
Prosodie
Au cours de l’élocution, la voix subit des variations à l’échelle de la syllabe, du mot, du tronçon, du groupe de souffle , de la phrase, du paragraphe. Ces variations, volontaires ou non, contribuent au naturel, à l’intelligibilité et à l’expressivité de la parole. Elles portent sur les trois principaux paramètres de variation de la parole : hauteur, intensité, vitesse, ainsi que sur la qualité vocale, beaucoup plus difficile à modéliser. En l’absence de prosodie, la voix paraît plate et monotone.
Modèle prosodique à base de contours naturels
À partir d’enregistrements variés (récits, exposés, interviews, dialogues), on extrait des contours prosodiques naturels, constitués des paramètres acoustiques de hauteur, intensité et vitesse de chaque tronçon. Chaque contour est associé à une clé, représentation mathématique des contraintes syntaxiques, pragmatiques et rythmiques auxquelles il est soumis (notamment taille du tronçon en syllabes, accent de mot pour l’anglais, position, fonction, distribution de l’information, ponctuation). Plusieurs centaines de contours sont actuellement intégrés dans le modèle, pour le français comme pour l’anglais. Grâce à ces ressources, 82 % des tronçons rencontrés en corpus trouvent un contour naturel adéquat en français – 67 % en anglais, l’accent de mot augmentant la combinatoire.
Modèle prosodique normalisé
Un modèle prosodique normalisé superpositionnel qui ne traite que la déclinaison, les pauses et les accents démarcatifs a été créé dès le début du projet. Bien que la prosodie obtenue soit un peu répétitive et manque de naturel, elle était régulière et fluide. Depuis 2010, ce modèle a progressivement cédé la place au modèle naturel. Parallèlement le modèle normalisé s’est amélioré, car il reste nécessaire, d’une part comme modèle par défaut pour fournir un contour aux tronçons qui n’en ont pas trouvé, d’autre part comme guide autour duquel le modèle naturel peut varier sans toutefois s’en écarter exagérément, afin de réduire les variations excessives ou inopportunes parfois présentes dans les contours, tout en conservant une importante part de naturel. Ce nouveau modèle plus fin est moins superpositionnel, comporte davantage de paramètres et est fabriqué automatiquement à partir de moyennes sur un certain nombre de caractéristiques des contours en mémoire. Ainsi extrait des données naturelles, il fournit de meilleurs contours par défaut et un meilleur encadrement des contours naturels.
Génération de la prosodie
Grâce aux balises d’analyse présentes dans le texte phonétique, le générateur de prosodie fabrique d’abord l’enveloppe prosodique normalisée à partir des paramètres du modèle. Puis il va chercher dans la base le contour prosodique naturel qui convient le mieux à chaque tronçon (calcul de la distance entre la clé d’analyse et les clés de la base grâce à une fonction de coût). Les contours absents sont remplacés par ceux du modèle normalisé. L’enveloppe prosodique naturelle est obtenue par concaténation des contours sélectionnés. Après application d’un calcul correctif en fonction de la distance avec le contour normalisé, l’enveloppe résultante est calculée. Elle définit l’ensemble des variations à appliquer au signal de parole.
Synthèse par diphones
Les langues comportent pour la plupart entre 25 et 50 phonèmes. Certains phonèmes présentant plusieurs réalisations phonétiques possibles, on parlera plutôt de phones pour désigner chaque réalisation. A partir de la voix d’un locuteur, on extrait une base de diphones, c’est-à-dire entre 1000 et 2000 segments de signal – selon la langue – qui seront ensuite normalisés et concaténés pour former le signal acoustique de parole. Chaque segment s’étend de la moitié d’un phone à la moitié du suivant. L’interface entre les segments étant le phone, le nombre de segments différents nécessaires à la fabrication de n’importe quel énoncé reste inférieur ou égal au carré du nombre de phones de la langue.
Génération de la parole
Le générateur de parole convertit la chaîne phonétique en un signal de parole par concaténation des diphones de la base. Les variations prosodiques calculées sont appliquées en temps réel. Le signal de parole est envoyé en continu vers les haut-parleurs à fréquence d’échantillonnage constante. Cette tâche se fait en même temps que les autres tâches de l’ordinateur : le programme de l’utilisateur reste actif et peut par exemple modifier les réglages, demander où en est la parole, l’interrompre, etc.
Les diphones étant normalisés, leur concaténation est possible sans modification. Le signal obtenu est une voix sans prosodie. Cela ne signifie pas que ce signal soit perçu comme une voix chantée sur une même note : en effet, sa fréquence fondamentale n’est pas constante du fait de la micro-prosodie intrinsèque à chaque diphone. La perception est celle d’une voix plate, mais parlée.
Avant de concaténer les diphones, le générateur de parole calcule l’enveloppe prosodique de tout l’énoncé, voyelle par voyelle (voir génération de la prosodie). Ensuite, durant la fabrication de la parole, la prosodie est calculée pour chaque période du signal par interpolation polynomiale d’ordre 5 pour l’intensité et la hauteur, linéaire pour la durée. Les balises de modification locale de durée ’:’ et ’<>’ produits par la transcription graphème-phonème sont elles aussi interprétées durant la fabrication de la parole, les valeurs associées étant superposées à celles de prosodie. D’autres balises de ce type peuvent être créées et utilisées par la transcription. Toutes sont définies dans un fichier, associées à leurs paramètres : variation de hauteur, intensité et durée, type (action sur le phonème suivant, encadrement d’un groupe de phonèmes, ou allongement de la partie centrale du phonème précédent).
Les variations d’intensité sont appliquées aux échantillons sous forme d’un facteur multiplicatif progressif. Les variations de hauteur et de durée font l’objet d’un traitement particulier sur les périodes (ci-dessous).
Au fur et à mesure de sa construction, le signal de parole est envoyé dans le tampon de la carte-son qui le diffuse à la fréquence d’échantillonnage de 22 050 Hz. Les codes d’index présents dans le texte, comptés dès le début des opérations, ont traversé les différents modules jusqu’au texte phonétique. Chaque fois que le générateur de parole les rencontre, il les décompte et les associe aux échantillons envoyés dans le tampon. Pendant ce temps, le programme de l’utilisateur reste disponible pour d’autres tâches (ce qui lui permet par exemple de demander la position de lecture ou de l’arrêter), le traitement du signal étant effectué en tâche de fond.
Modification de la fréquence fondamentale et de la durée
Les méthodes utilisées pour modifier la fréquence fondamentale et la durée se font en restant dans le domaine temporel, ce qui présente l’avantage de nécessiter relativement peu de calculs, et par conséquent de pouvoir les appliquer en temps réel pendant la production de la parole, tout en conservant au mieux la qualité du timbre original.
Le principe est le suivant : le signal de période courante T est découpé en signaux élémentaires de largeur 2T, résultant du produit du signal d’origine par une fenêtre sinusoïdale, de largeur 2T, centrée sur la partie de plus forte énergie de chaque période. Si on ne change rien, la somme des signaux élémentaires, qui se recouvrent mutuellement sur la largeur d’une période, reproduit le signal d’origine (figure).
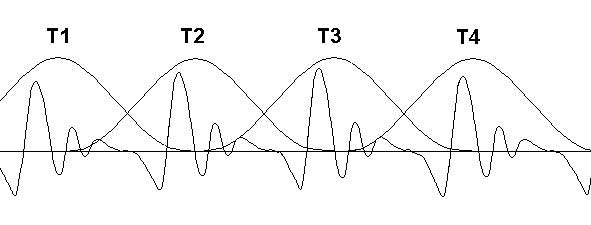
La diminution de la période consiste à faire glisser les signaux élémentaires sans les déformer en diminuant la largeur des fenêtres sinusoïdales, de façon à conserver une répartition uniforme de l’énergie. L’augmentation de la période consiste en l’opération inverse, à ceci près qu’il n’est pas souhaitable de dilater les fenêtres, car, trop larges, elles contiendraient alors des traces non négligeables de la périodicité d’origine, créant des phénomènes de réverbération préjudiciables à la qualité de la parole. Les fenêtres sont donc écartées sans modification, ce qui réduit sensiblement l’intensité mais ne détériore pas significativement la qualité de la voix synthétique. En revanche, les parties non ou peu voisées (en pratique inférieures à un certain taux de voisement) dont la périodicité est absente ou négligeable, peuvent bénéficier de la dilatation des fenêtres, évitant ainsi un phénomène de périodisation, qui serait lui aussi préjudiciable à la qualité de la voix.
La modification de durée (ou de son inverse, la vitesse de phonation) est effectuée en dupliquant ou en retirant des signaux élémentaires.
L’évaluation perceptive de nos méthodes de modification nous a permis d’obtenir les résultats suivants (F0 = fréquence fondamentale, V = vitesse de phonation) :
- F0 ± 3 tons : détérioration négligeable
- F0 ± 1 octave : détérioration nette (acceptabilité moyenne)
- V x 2 ou V / 2 : détérioration faible (mais effet d’excès ou d’insuffisance articulatoire)
- V x 3 ou V / 3 : détérioration nette (acceptabilité moyenne)
Les variations maximales dues à la prosodie dépassent rarement 3 tons sur la fréquence fondamentale et un rapport 2 localement sur les durées. En conséquence, nos méthodes de modification ont peu d’influence sur la qualité finale de la voix synthétique.
Fonctions de Kali (réglages généraux de la voix)
- Hauteur : 0 à 15, valeur de base 6, incrémentation par demi-tons, soit des rapports de 1,0595
- Débit : -2 à 20 (initialement 0 à 15), valeur de base 5, incrémentation par tons, soit des rapports de 1,1225
- Volume : 0 à 15, valeur de base 10, incrémentation par l’équivalent de 2 tons en amplitude, soit des rapports de 1,26
- Voix
- Langue
- Mode de lecture : littéraire, sans abréviations, dictée ou calcul
- Mode comptabilité (utilisation de séparateurs de milliers)
- Mode épellation internationale (de type alpha bravo charlie)
- Mode hyper-articulé (voix très lente et ajout de nombreux e muets et liaisons)
- Quantité de prosodie : 0 à 16, valeur de base 8 (facteur multiplicatif)
- Silence : 0 à 16, valeur de base 8 (durée relative des silences dus à la ponctuation)
- Prosodie naturelle : 0 à 16, valeur de base 8 (0 = prosodie normalisée, 16 = relâchement maximal de la contrainte sur les contours naturels)
Ces réglages peuvent également être effectués en plaçant des balises dans le texte aux endroits où ils doivent s’appliquer.
Commandes de Kali
- Lecture du texte
- Demande de la position de lecture dans le texte
- Arrêt immédiat de la lecture