
Principe
Lorsqu’on introduit un lien synonymique manquant entre deux termes, on remarque souvent des possibilités de nouveaux liens parmi leurs synonymes respectifs. L’idée est donc d’étudier le statut des synonymes du second ordre (les « synonymes de synonymes » sans lien synonymique direct). L’examen de ceux-ci – dont le nombre dépasse un million dans la base du DES, contre 200 000 liens avérés – montre une faible probabilité de synonymie, qui s’explique par la polysémie des synonymes intermédiaires.
Il s’agit d’utiliser les liens déjà répertoriés pour trouver une grande partie des liens manquants, donc de compléter les ressources grâce à celles que l’on possède déjà. La méthode se base sur le principe de la transitivité partielle de la synonymie (MANGUIN 2004), à la différence que nous ne cherchons pas ici à générer des liens sûrs, c’est-à-dire à fixer un seuil qui séparerait les liens acceptables de ceux qui ne le seraient pas. L’intervention humaine reste toujours indispensable, car même les liens calculés comme les plus probables comportent un taux d’erreur. Par exemple, châtaigneraie et hêtraie possèdent 3 synonymes communs : bois, futaie et plantation, et aucun autre synonyme, donc un taux de synonymes partagés de 100 %. Pourtant, leur relation ne relève pas de la synonymie, mais de la co-hyponymie. A l’inverse, des candidats obtenant un score médiocre peuvent se révéler pertinents. Par exemple, prouvé et établi comptent 4 synonymes communs (avéré, certain, irréfragable, sûr), mais respectivement 4 et 21 synonymes non partagés, soit un taux de 50 % d’un côté et de 16 % de l’autre. Ne cherchant plus à trouver une formule de calcul idéale, nous avons testé diverses formules afin de mettre à l’épreuve nos hypothèses.
Le DES est représenté mathématiquement par un graphe dont les sommets sont les unités lexicales (les entrées du DES) et les arrêtes les liaisons synonymiques. Notre hypothèse est que plus le nombre de synonymes – et d’antonymes – partagés par deux synonymes du second ordre est élevé, plus la probabilité d’un lien synonymique oublié est grande. A l’inverse, plus le nombre de synonymes – et d’antonymes – de l’une ou l’autre des deux entrées, non partagés, est élevé, plus la divergence sémantique est probable.
Le programme de calcul des liens manquants probables commence donc par dresser une liste des synonymes d’ordre 2, reliés soit par des synonymes, soit par des antonymes. Nous étendons notre hypothèse aux antonymes d’ordre 2, reliés par des entrées qui sont chacune synonyme de l’un et antonyme de l’autre.
Soient les entrées E1 et E2, synonymes d’ordre 2. Nous utilisons trois valeurs : n1 = nombre de synonymes + antonymes de E1, n2 = nombre de synonymes + antonymes de E2, et c = nombre de synonymes + antonymes communs à E1 et E2. Le nombre c est toujours inférieur ou égal à n1 et à n2, mais doit s’en rapprocher pour répondre à nos critères. Plusieurs formules pour obtenir un score de proximité sémantique sont comparées. Le principe est le même pour les antonymes.
Formules
La première formule considère le taux de synonymes + antonymes communs par rapport à l’ensemble des synonymes + antonymes des deux entrées. Ce taux atteint 100 % quand tous les synonymes et antonymes sont communs (dans le cas limite où c = n1 = n2).
Score s1 = c/(n1+n2-c)
La deuxième formule tient compte d’un phénomène souvent observé : lorsque l’une des entrées possède moins de synonymes + antonymes que l’autre, parfois beaucoup moins, mais que tous ou presque sont communs, le lien est souvent validé. Il nous a donc semblé intéressant d’utiliser une formule qui ne prend en compte que le « meilleur côté » :
Score s3 = max (c/n1 ; c/n2)
Là encore, le maximum possible est de 100 %. Nous avons noté ce score « s3 », car nous utilisons également une formule intermédiaire, dans laquelle le « meilleur côté » est légèrement favorisé :
Score s2 = moy (c/n1 ; c/n2)
Ces trois formules permettent de tester si le « meilleur côté » doit être plus ou moins favorisé. Un autre point que nous avons voulu tester est l’influence de la quantité : faut-il accorder une plus grande importance au nombre de synonymes + antonymes communs qu’au nombre de synonymes + antonymes non communs ? En d’autres termes, le score (purement qualitatif dans les formules précédentes) doit-il être modulé selon des critères quantitatifs ?
Nous avons pour cela introduit une constante dans les formules afin de favoriser un peu (s+), moyennement (s++), beaucoup (s+++) l’aspect quantitatif. Le cas « pas du tout » (s) a été éliminé rapidement, car donnant des résultats nettement moins bons. Il y a donc en tout 3 x 3 = 9 formules.
Résultats des premiers essais en 2013
Au total, une fois les scores classés par ordre décroissant, toutes formules confondues, sur 691 propositions de liens, 581 ont été validées, soit 84,1%.
Taux de succès des formules :
s1 : 83,7 % ; s2 : 84,3 % ; s3 : 88,3 %
Il est donc intéressant de choisir le score du « meilleur côté ».
Concernant l’aspect quantitatif, les taux de succès sont les suivants :
s+ : 80,0 % ; s++ : 87,3 % ; s+++ : 88,8 %
La quantité de synonymes joue un rôle, il ne faut pas se contenter d’un score qualitatif.
Évolution des résultats entre 2013 et 2016
Toutes les formules ayant un bon rendement, nous avons continué avec les neuf afin de compléter la base de données dans toute sa richesse. Nous avons cependant décalé les formules s++ et surtout s+++ de façon à augmenter les différences dues à la quantité.
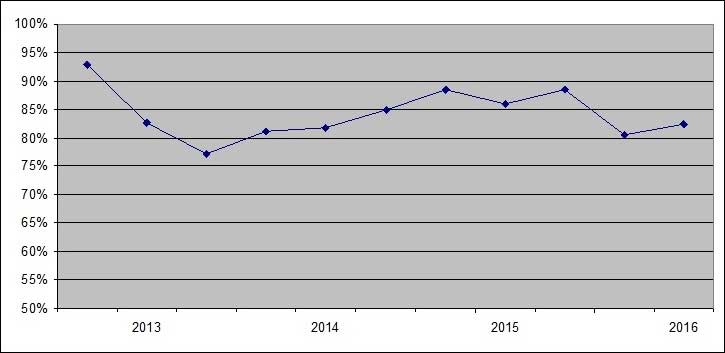
Une décroissance exponentielle de l’efficacité au cours du temps est vraisemblable. Une étude de cette décroissance sur plusieurs années au rythme des 600 liens étudiés par an devrait permettre de calculer une estimation du nombre de liens manquants résiduels et de son évolution dans le temps. La figure ci-dessous montre un rebond important, dont la cause est à l’étude, et ne permet pas encore d’évaluer la ligne directrice de la décroissance exponentielle attendue, au bout de 4 ans et 2400 liens étudiés ; on peut seulement déduire de la faible variation globale, que le nombre de liens manquants est probablement supérieur à 20000, soit plus de 10% du total.
Exemples
Quelques exemples de liens synonymiques acceptés :
- déchiffrage – décryptage
- pioncer – roupiller
- barjo – givré
- dérouillée – rouste
- coup de chien – coup de tabac
- séance tenante – tout de suite
- enfiévrer – survolter
- bleuté – céruléen
Ces liens manquants sont manifestement des oublis.
Quelques exemples de liens antonymiques acceptés :
- chiffonner | défriper
- analogie | dissimilitude
- modéré | outrancier
- exécutable | infaisable
- calmer | mettre en colère
- attractif | repoussant
Quelques exemples de liens synonymiques refusés :
- châtaigneraie # hêtraie
- argenter # nickeler
- némésis # vendetta
- anthracite # lignite
- javeline # sagaie
- douzain # dizain
Les liens refusés relèvent presque tous de la co-hyponymie.
Conclusion
Cette méthode nous permet de compléter les ressources grâce à celles que l’on possède déjà, ce qui revient à densifier le graphe du DES. Le potentiel de progression est important, avec plus de 20000 relations à trouver. Il est donc souhaitable d’utiliser régulièrement l’outil de génération des liens probables pour faire progresser sensiblement la base de synonymes et d’antonymes.
Cependant, cette méthode ne permet pas de raccorder des espaces sémantiques indépendants, dont l’indépendance serait due à un oubli. La collaboration des utilisateurs grâce à l’interface de proposition nous donne l’opportunité d’établir de telles connexions, ainsi que d’ajouter de nouvelles entrées et des liens correspondant à des acceptions nouvelles.