
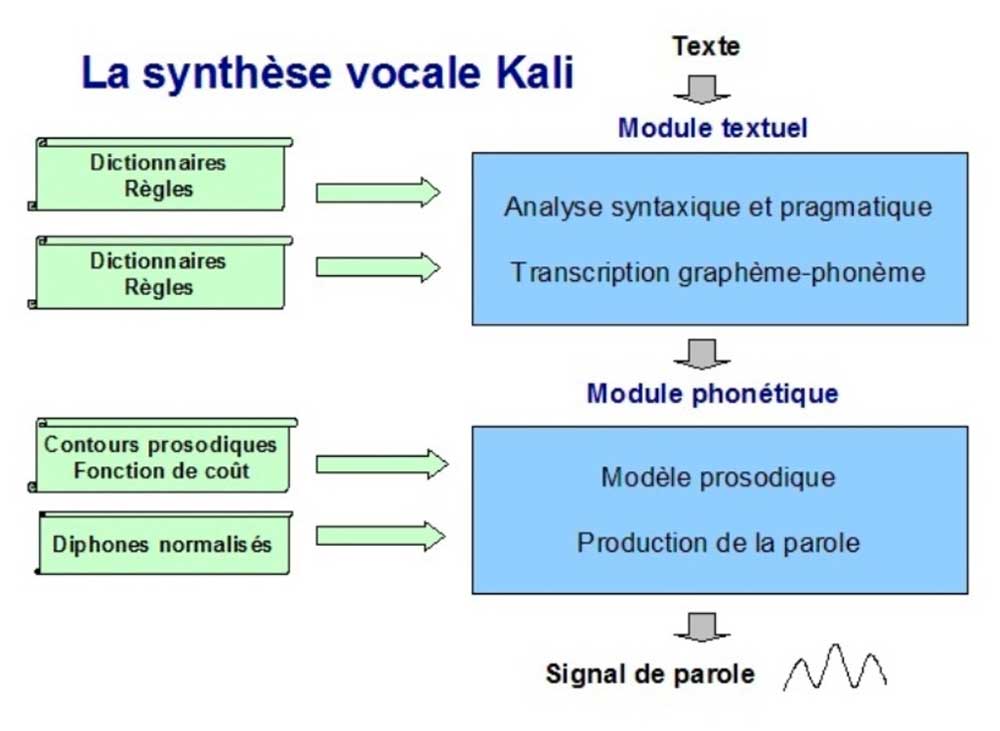
Pour être converti en parole, le texte à prononcer traverse successivement deux modules : le module textuel et le module phonétique.
Le module textuel est composé de deux opérations : (1) l’analyse syntaxique et pragmatique, (2) la transcription graphème-phonème. Chaque opération repose sur une exploitation déclarative des connaissances, sous forme de dictionnaires et de règles. Cette conception déclarative des ressources linguistiques permet de passer rapidement d’une langue à une autre, seules les données (dictionnaires et règles) changent, les outils de traitement restant les mêmes. Par ailleurs, une telle architecture facilite la lisibilité, la correction et l’évolution des règles développées au sein de chaque module, donc la maintenance générale du système. Au cours du traitement, l’analyse syntaxique et pragmatique pose des balises représentant la structure du texte destinée à servir d’entrée au modèle prosodique. La transcription graphème-phonème transforme ensuite le texte alphabétique en texte phonétique, avec transfert des balises syntactico-pragmatiques.
Le module phonétique est composé lui aussi de deux opérations : (1) le modèle prosodique, (2) la production de la parole. Le modèle prosodique reçoit en entrée le texte phonétique enrichi des balises syntactico-pragmatiques. Ces données lui permettent de calculer les paramètres acoustiques représentant l’enveloppe prosodique de la parole. Il utilise comme ressources linguistiques les paramètres du modèle prosodique normalisé, une base de contours prosodiques naturels ainsi qu’une fonction de coût destinée à choisir chaque contour. La production de la parole reçoit en entrée le texte phonétique et fournit en sortie les échantillons du signal sonore. Elle utilise pour chaque voix une base de diphones normalisés, ceux-ci étant juxtaposés et modifiés en temps réel par l’enveloppe prosodique. Les ressources utilisées par le module phonétique sont fabriquées à l’aide d’un logiciel interactif de développement à base de traitement du signal. Les contours prosodiques sont générés par ce logiciel sous forme de petits fichiers texte. Ils sont modifiables et exploitables par ailleurs pour l’analyse des paramètres acoustiques de la parole. De leur côté, les bases de diphones, par nature non déclaratives, sont fabriquées à l’aide de ce même logiciel.